Attention
Cate has become the ESA Climate Toolbox. This documentation is being discontinued. You can find the documentation on the ESA Climate Toolbox here.
7. Architecture
This chapter describes the internal, technical design of the CCI Toolbox that has been developed on the basis of the CCI Toolbox User Requirements Document (URD), the climate data exploitation Use Cases defined in the URD, as well as the abstract Operation Specifications that have been derived from both.
This architecture description tries to reflect the current software design of the CCI Toolbox and should provide the big picture of the software to the development team and should help other programmers getting an overview.
Please note that this architecture description does not necessarily reflect the CCI Toolbox application programming interface (API). The actual public API comprises a relatively stable subset of the components, types, interfaces, and variables describes here and is described in chapter API Reference.
7.1. Overview
The CCI Toolbox at its basis is a Python package cate which provides the a command-line interface (CLI), application
programming interface (API), and a web API interface (WebAPI), and also implements all required climate data
visualisation, processing, and analysis functions. It defines a common climate data model and provides a common
framework to register, lookup and invoke operations and workflows on data represented in the common data model.
The CCI Toolbox graphical user interface, Cate App, is a web application that communicates the Python core via its WebAPI. The WebAPI is either provided as a software-as-a-service in the cloud, or the user can run its own local server.
The ESA CCI Open Data Portal is the central climate data provider for the CCI Toolbox. It provides time series of essential climate variables (ECVs) in various spatial and temporal resolutions in netCDF and Shapefile format. At the time of writing (June 2016), the only operational data access service is via FTP. However, the CCI Open Data Portal will soon offer also data access via a dedicated THREDDS server and will support OPEeNDAP and OGC WCS services.
The following Fig. 7.1 shows the CCI Toolbox GUI, CCI Toolbox Python core, and the CCI Open Data Portal.
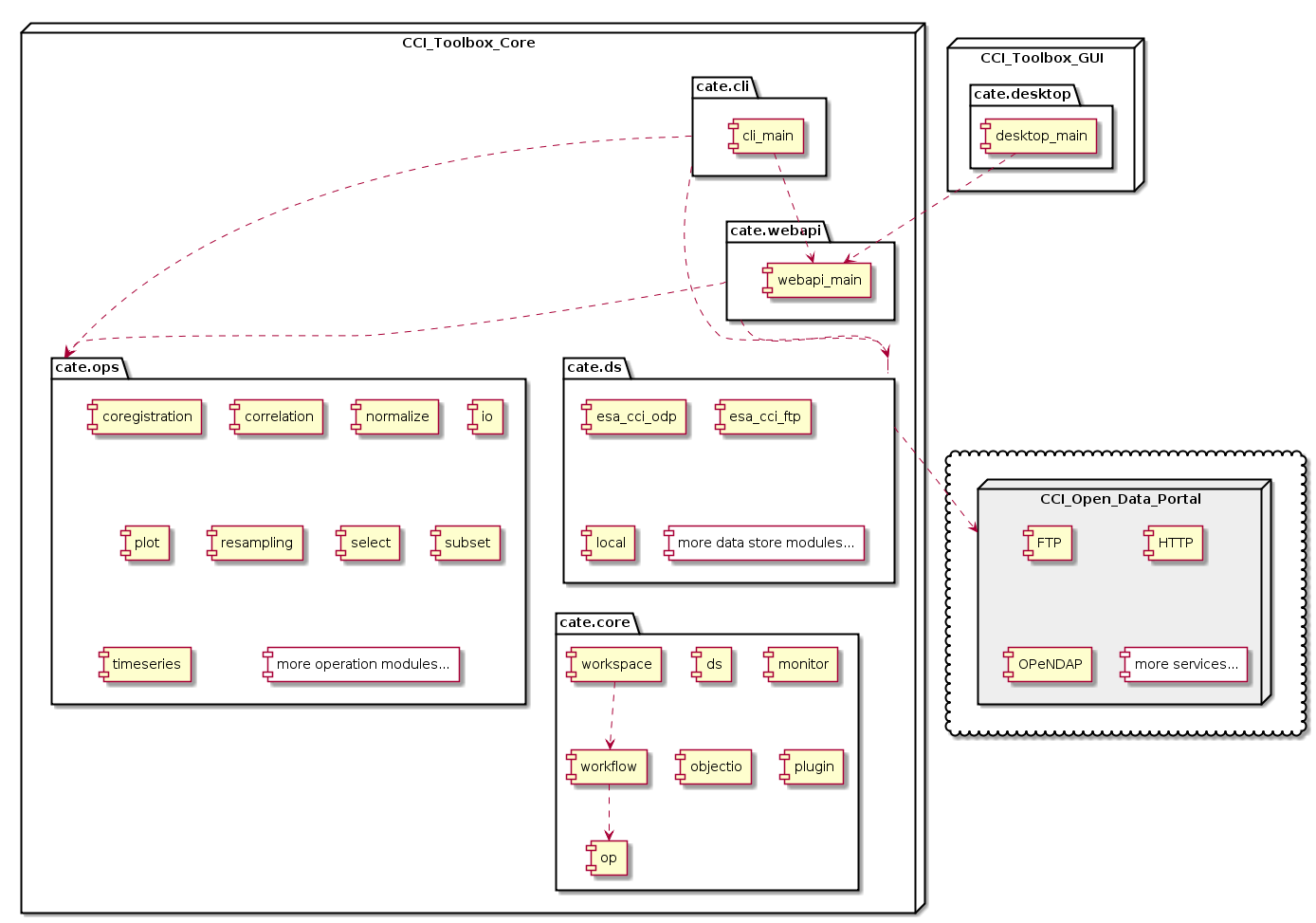
Fig. 7.1 CCI Toolbox GUI, CCI Toolbox cate package, and the CCI Open Data Portal.
Note that although the CCI Toolbox GUI and Python core are shown in Fig. 7.1 as separate nodes, they are combined in one software installation on the user’s computer.
The CCI Toolbox Python package comprises several sub-packages of which are described in the following four sections.
7.1.1. Package cate.core
The cate.core Python package is most import part of the CCI Toolbox architecture. It provides a common framework for
climate data I/O and processing. Although designed for climate tooling and use with climate
data the framework and API is more or less application-independent.
The cate.core package
defines the CCI Toolbox’ common data model
provides the means to read climate data and represent it in the common data model
provides the means to process / transform data in the common data model
to write data from the common data model to some external representation
As a framework, cate.core allows plugins to extend the CCI Toolbox capabilities. The most interesting extension
points are
climate data stores that will be added to the global data store registry
climate data visualisation, processing, analysis operations that will be added to the global operations registry
The cate.core packages comprises the essential modules which described in more detail in the following sub-sections:
module
ds- Data Stores and Data Sourcesmodule
op- Operation Managementmodule
workflow- Workflow Managementmodule
objectio- Object Input/Outputmodule
plugin- Plugin Concept
7.1.2. Package cate.ds
The Python package cate.ds contains specific climate data stores (=ds). Every module in this package is
dedicated to a specific data store.
The
esa_cci_odpmodule provides the data store that allows opening datasets provided by the ESA CCI Open Data Portal (ODP). More specifically, it provides data for theesaciientry in the ESGF data service.The
esa_cci_ftpmodule provides the data store that allows opening datasets provided by the FTP service of the ESA CCI Open Data Portal. This data store is now deprecated in favour of the ESGF service.
The package cate.ds is a plugin package. The modules in cate.ds are activated during installation
and their data sources are registered once the module is imported. In fact, no module in package cate.core
has any knowledge about the package cate.ds and users never deal with its modules directly.
Instead, all registered data stores are accessible through the cate.core.ds.DATA_STORE_REGISTRY singleton.
7.1.3. Package cate.ops
The Python package cate.ops contains (climate-)specific visualisation, processing and analysis functions.
Every module in this package is dedicated to a specific operation implementation.
For example the timeseries module provides an operation that can be used to extract time series from
datasets. Section Operation Management describes the registration, lookup, and invocation of operations,
section Workflow Management describes how an operation can become part of a workflow.
The chapter Operation Specifications provides abstract descriptions of the individual operations in this package.
Similar to cate.ds, the package cate.ops is a plugin package, only loaded if requested, and no module in
package cate.core has any knowledge about the package cate.ops.
7.1.4. Package cate.cli
The package cate.cli comprises a main module, which implements the CCI Toolbox’ command-line interface.
The command-line interface is described in section Command-Line Interface.
7.1.5. Package cate.webapi
The package cate.webapi implements the CCI Toolbox’ WebAPI which implements a web service that allows using the
CCI Toolbox Python API from the
* Cate App GUI as well as
* the interactive commands of the CLI.
7.1.6. Package cate.util
The cate.util package is fully application-independent and can be used stand-alone. Numerous,
CCI Toolbox API functions take a monitor argument used for progress monitoring of mostly long-running tasks.
The cate.util.monitor package defines the Monitor class.
module
monitor- Task Monitoring
7.1.7. Package cate.conf
The cate.conf package provides Cate’s configuration API. The cate.conf.defaults module defines the default
values for Cate’s configuration parameters.
7.2. Common Data Model
The primary data source of the first releases of the CCI Toolbox are the data products delivered by the ESA CCI programme. Later in the project, the CCI Toolbox will also address other datasets.
The majority of the gridded ECV datasets from ESA CCI are in netCDF-CF format, which is a de-factor standard in climate science. The datasets of the Land Cover CCI are provided in GeoTIFF format and the Glaciers and Ice Sheets CCIs deliver their datasets in ESRI Shapefile format.
Ideally, the CCI Toolbox could combine the various datasets in a single common data model so that an API could be designed that allows a uniform and transparent for data access. This would also allow to make a maximum of operations work on both raster and vector data.
As this sounds reasonable at first, the team has decided not go for such a grand unification as the way how gridded raster data is processed is substantially different from how vector data is processed. To make the majority of data operations applicable to both data types, rasterisation (or vectorisation) would need to occur implicitly and would need to be controlled by explicit operation parameters.
Instead, the CCI Toolbox stays with the Unidata Common Data Model and CF Conventions for raster data, and the Simple Features Standard (ISO 19125) for vector data. This is achieved by reusing the data models and APIs of the popular, geo-spatial Python libraries.
7.2.1. Raster Data
For the representation of raster or gridded data, the CCI Toolbox relies on the xarray Python library.
xarray builds on top of numpy, the fundamental package for scientific computing with Python,
and pandas, the Python Data Analysis Library.
The central data structure in the CCI Toolbox is xarray.Dataset, which is an in-memory representation of the data
model from the netCDF file format. Because of its generality for multi-dimensional arrays, it is also well-suited to
represent the GeoTIFF and other raster and gridded data formats. The xarray.Dataset structure is composed of the
following elements and follows the Unidata Common Data Model:
- Variables
are containers for the dataset’s geo-physical quantities. They are named, multi-dimensional arrays of type xarray.DataArray which behave quite like numpy ndarrays. The dataset variables are accessible through the
data_varsattribute, which is mapping from variable name to the multi-dimensional data arrays.- Coordinates
To label the grid points contained in the variable arrays, coordinates are used. Coordinates are also xarray.DataArray instances and are accessible through the
coordsattribute, which is a mapping from coordinate names to the usually one-dimensional label arrays.- Dimensions
All dimensions used by the variables and coordinates arrays are named and have a size. The mapping from dimension name to size is accessible through the
dimsattribute.- Attributes
are used to hold metadata both for
xarray.Datasetandxarray.DataArrayinstances. Attributes are accessed by theattrsattribute which is a mapping from attribute names to arbitrary values.
7.2.2. Vector Data
From version 1.0 on, the representation of vector data will be provided by utilising the GeoPandas Python library.
Similar to xarray, also GeoPandas relies on pandas, the Python Data Analysis Library.
Once the CCI Toolbox supports vector data, it will provide a rasterisation operation in order to convert vector data into the raster data model, namely xarray.Dataset instances.
7.3. Data Stores and Data Sources
In the CCI Toolbox, a data store represents something that can be queries for climate data sources.
For example, the ESA CCI Open Data Portal currently (June 2016) provides climate data products for around 13 essential climate variables (ECVs). Each ECV comes in different spatial and temporal resolutions, may originate from various sensors and may be provided in various processing versions. A data source refers to such a unique ECV occurence.
The cate.core.ds module comprises the following abstract types:
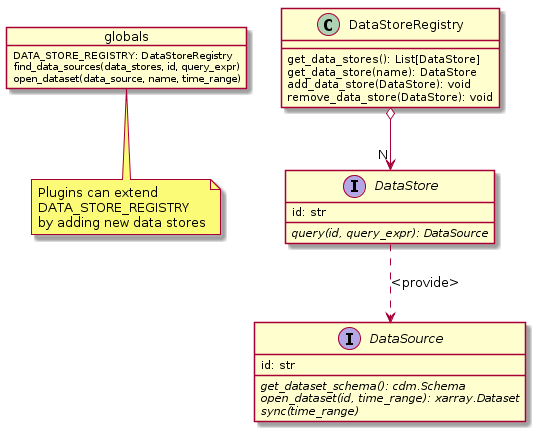
Fig. 7.2 DataStore and DataSource
The DataStoreRegistry manages the set of currently known data stores. The default data store registry is accessible
via the variable DATA_STORE_REGISTRY. Plugins may register new data stores here. There will be at least one
data store available which is by default the data store that mirrors parts of the FTP tree of CCI Open Data Portal
on the user’s computer.
The DataStore.query() allows for querying a data store for data sources given some optional constraints.
The actual data of a data source can be provided by calling the DataSource.open_dataset() method
which provides instances of the xarray.Dataset type which has been introduced in the former section Package cate.util.
The DataSource.sync() method is used to explicitly synchronise the remote content of a data store
with locally cached data.
7.4. Operation Management
The CCI Toolbox cate.core.op module allows for the registration, lookup and controlled invocation of
operations. Operations can be run from the CCI Toolbox command-line (see next section Command-Line Interface),
may be referenced from within processing workflows (see next section Workflow Management), or may be invoked from
from the WebAPI (see Fig. 7.1) as a result of a GUI request.
An operation is represented by the Operation type which comprises any Python
callable (function, lambda expression, etc.) and some additional meta-information OpMetaInfo that describes the
operation and allows for automatic input validation, input value conversion, monitoring. The OpMetaInfo object
specifies an operation’s signature in terms of its expected inputs and produced outputs.
The CCI Toolbox framework may invoke an operation with a Monitor object, if the operation supports it. The operation
can report processing progress to the monitor or check the monitor if a user has requested to cancel the (long running)
operation.

Fig. 7.3 OpRegistry, Operation, OpMetaInfo
Operations are registered in operation registries of type OpRegistry, the default operation registry is
accessible via the global, read-only OP_REGISTRY variable. Plugins may register new operations. A convenient way for
developers is to use specific decorators that automatically register an annotated Python function or class
and add additional meta-information to the operation registration’s OpMetaInfo object. They are
@op(properties)registers the function as operation and adds meta-information properties to the operation.@op_input(name, properties)adds extra meta-information properties to a named function input (argument)@op_output(name, properties)adds extra meta-information properties to a named function output@op_return(name, properties)adds extra meta-information properties to a single function output (return value)
Note that if a Python function defines an argument named monitor, it will not be considered as an operation input.
Instead it is assumed that it is a monitor instance passed in by the CCI Toolbox, e.g. when invoking an operation from the
command-line or if an operation is performed as part of a workflow as described in the next section.
7.5. Workflow Management
Many analyses on climate data can be decomposed into some sequential steps that perform some fundamental operation.
To make such recurring chains of operations reusable and reproduceable, the CCI Toolbox contains a simple but powerful
concept which is implemented in the cate.core.workflow module.
A workflow is a network or to be more specific, a directed acyclic graph of steps. A step execution may invoke a registered operation (see section Operation Management), may evaluate a simple Python expressions, may spawn an external process, and invoke another workflow.
An great advantage of using workflows instead of, e.g. programming scripts, is that that the invocation of steps is controlled and monitored by the CCI Toolbox framework. This allows for task cancellation by users, task progress reporting, input/output validation. Workflows can be composed by a dedicated GUI or written by hand in a text editor, e.g. in JSON, YAML or XML format. Workflow steps can even be used to automatically ingest provenance information into the dataset outputs for processing traceability and later data history reconstruction.
Fig. 7.4 shows the types and relationships in the cate.core.workflow module:
A
Nodehas zero or more inputs and zero or more outputs and can be invoked.A
Workflowis aNodethat is composed ofStepobjects.A
Stepis aNodethat is part of aWorkflowand performs some kind of data processing.A
OpStepis aStepthat invokes anOperation.An
ExpressionStepis aStepthat executes a Python expression string.A
WorkflowStepis aStepthat executes aWorkflowloaded from an external (JSON) resource.
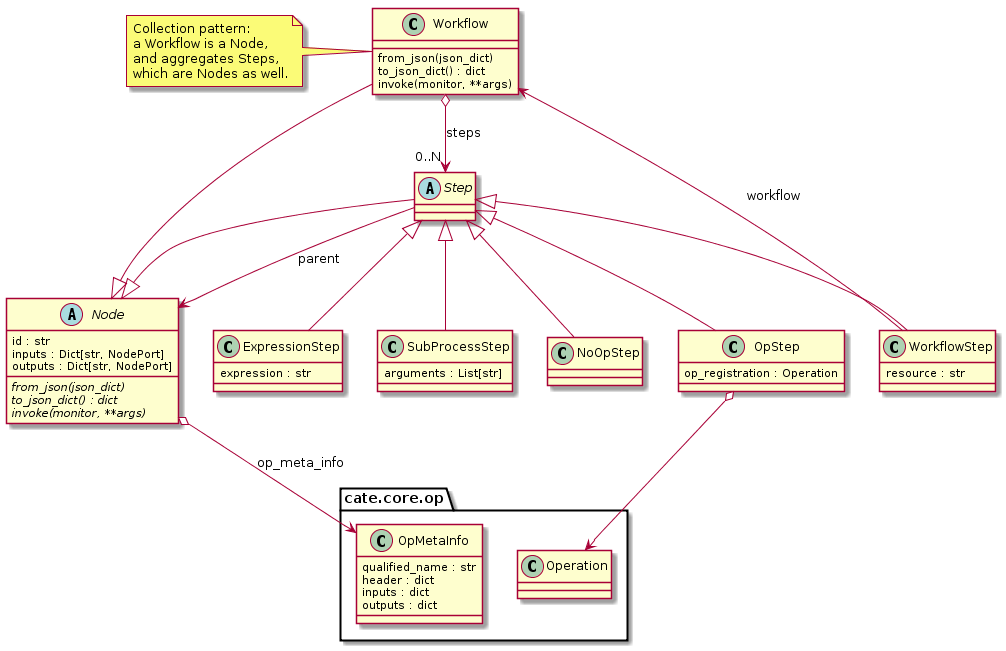
Fig. 7.4 Workflow, Node, Step
Like the Operation, every Node has an associated OpMetaInfo object specifying the node’s
signature in terms of its inputs and outputs. The actual Node inputs and outputs are modelled by the
NodePort class. As shown in Fig. 7.5, a given node port belongs to exactly
one Node and represents either a named input or output of that node. A node port has a name, a property
source, and a property value. If source is set, it must be another NodePort that provides the
actual port’s value. The value of the value property can be basically anything that has an external (JSON)
representation.
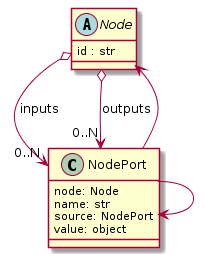
Fig. 7.5 Node and NodePort
Workflow input ports are usually unspecified, but value may be set.
Workflow output ports and a step’s input ports are usually connected with output ports of other contained steps
or inputs of the workflow via the source attribute.
A step’s output ports are usually unconnected because their value attribute is set by a step’s concrete
implementation.

Fig. 7.6 Workflow invokes its steps
Similar to operations, users can run workflows from the command-line (see section Command-Line Interface),
or may be invoked from the WebAPI (see Fig. 7.1) due to a GUI request. The CCI Toolbox will always
call workflows with a Monitor instance (see section Task Monitoring) and therefore sub-monitors will be passed to the
contained steps.
The workflow module is independent of any other CCI Toolbox module so that it may later be replaced by a
more advanced workflow management system.
7.6. Object Input/Output
The objectio module provides two generic functions for Python object input and output:
read_object(file, format)reads an object from a file with optional format name, if known.write_object(obj, file, format)writes an object to a file with a given format.
The module defines the abstract base class ObjectIO which is implemented by classes that read Python objects from
files and write them into files. ObjectIO instances represent a file format and the Python object types that
they can read from and write to files of that format. Therefore they can make a guess how suitable they are for reading
from a given file (method read_fitness(file)) or writing an object to a file (method write_fitness(obj)).
ObjectIO instances are registered in the OBJECT_IO_REGISTRY singleton which can be extended by plug-ins.
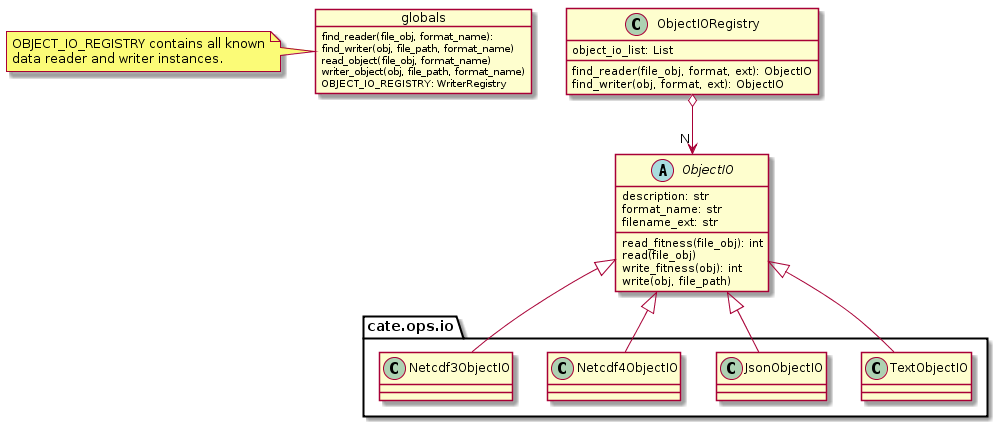
Fig. 7.7 ObjectIO and some of its implementations
7.7. Task Monitoring
The monitor module defines the abstract base class Monitor that that may be used by functions and methods
that offer support for observation and control of long-running tasks. Concrete Monitor``s may be implemented by
API clients for a given context. The ``monitor module defines two useful implementations.
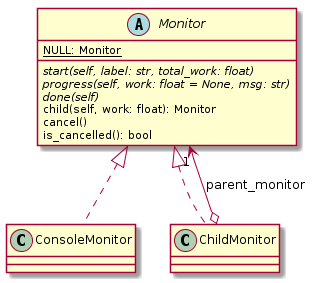
Fig. 7.8 Monitor and sub-classes
ConsoleMonitor: a monitor that is used by the command-line interfaceChildMonitor: a sub-monitor that can be passed to sub-tasks called from the current task
In addition, the Monitor.NONE object, is a monitor singleton that basically does nothing. It is used instead
of passing None into methods that don’t require monitoring but expect a non-None argument value.
7.8. Command-Line Interface
The primary user interface of the CCI Toolbox’ Python core is a command-line interface (CLI) executable named cate.
The CLI can be used to list available data sources and to synchronise subsets of remote data store contents on the user’s computer to make them available to the CCI Toolbox. It also allows for listing available operations as well as running operations and workflows.
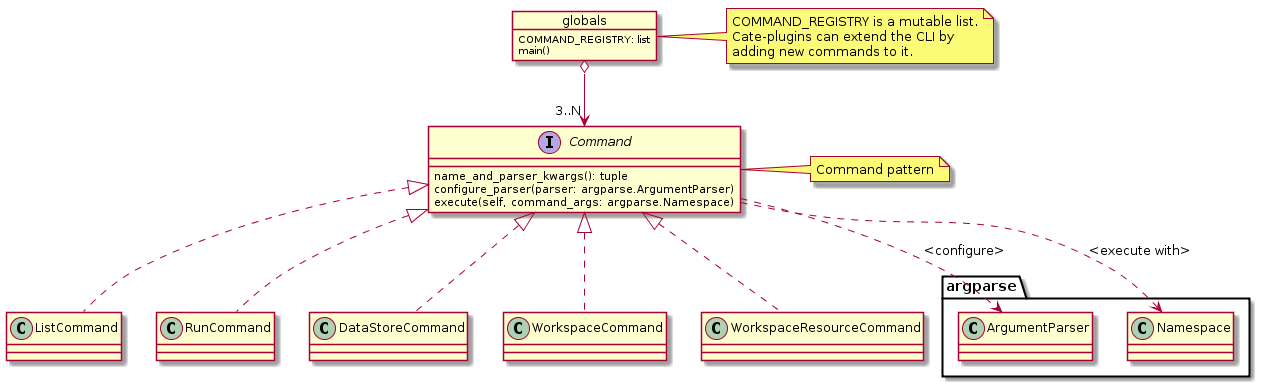
Fig. 7.9 CLI Command and sub-classes
The CLI uses (sub-)commands for specific functionality. The most important commands are
runto run an operation or a Workflow JSON file with given arguments.dsto manage data sources and to synchronise remote data sources with locally cached versions of it.opto list and display details about available operations.wsto manage user workspaces.resto add, compute, modify, and display resources within the current user workspace.
Each command has its own set of options and arguments and can display help when used with the option `--help
or -h.
Plugins can easily add new CLI commands to the CCI Toolbox by implementing a new Command class and registering it
in the COMMAND_REGISTRY singleton.
7.9. Plugin Concept
A CCI Toolbox plugin is actually any Python module that extend one of the registry singletons introduced in the previous sections:
Add a new
cate.core.ds.DataStoreobject tocate.core.ds.DATA_STORE_REGISTRYAdd a new
cate.core.op.Operationobject tocate.core.op.OP_REGISTRYAdd a new
cate.core.objectio.ObjectIOobject tocate.core.objectio.OBJECT_IO_REGISTRYAdd a new
cate.util.cli.Commandobject tocate.cli.COMMAND_REGISTRY
It could also be a Python module that modifies or extends existing CCI Toolbox types by performing some controlled monkey patching.
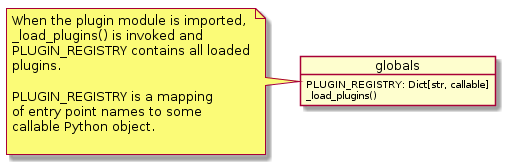
Fig. 7.10 The plugin module
The CCI Toolbox will call any plugin functions that are registered with the cate_plugins entry point
of the standard Python setuptools module. These entry points can be easily provided in the plugin’s
setup.py file. The value of each entry point must be a no-arg initialisation function, which is
called by the CCI Toolbox at given time. After successful initialisation the plugin is registered
in the PLUGIN_REGISTRY singleton.
In fact the cate.ds and cate.ops packages of the CCI Toolbox Python core are such plugins registered
with the same entry point:
setup(
name="cate",
version=__version__,
description='ESA CCI Toolbox',
license='MIT',
author='ESA CCI Toolbox Development Team',
packages=['cate'],
entry_points={
'console_scripts': [
'cate = cate.cli.main:main',
],
'cate_plugins': [
'cate_ops = cate.ops:cate_init',
'cate_ds = cate.ds:cate_init',
],
},
...
)
7.10. Software-as-a-Service (SaaS)
Cate Software-as-a-Service (SaaS) has been designed to deliver Cate software instances to users, so they do not need to install and configure the software on their own.
Cate SaaS does this by providing individual Cate service instances to logged-in users. These instances serve as backends for the Cate App. The Cate App can now be accessed via a dedicated URL in an internet browser and then installed as a desktop application (it is a Progressive Web Application, PWA).
The design of the Cate SaaS and the utilized software components makes it independent of the cloud providers. Cate SaaS tenants may be deployed on AWS, GCP, OTC, or any ESA DIAS.
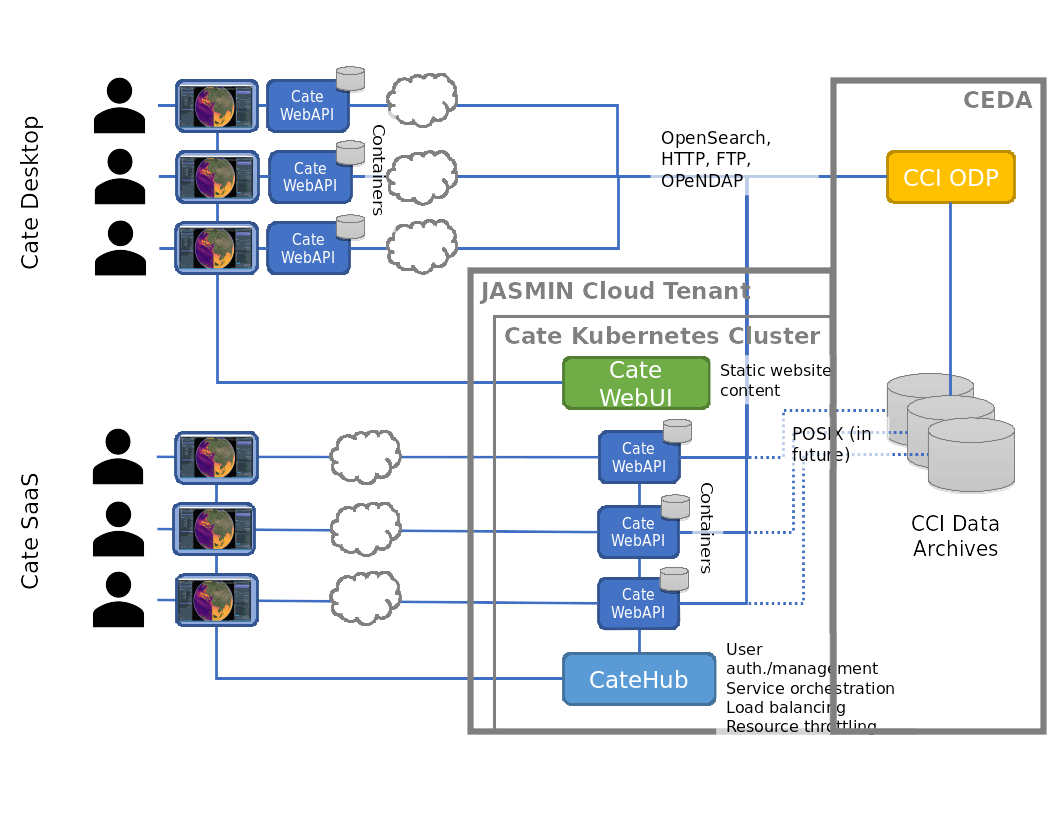
Fig. 7.11 High-level architecture of Cate SaaS.
The figure above illustrates the major components of the Cate SaaS and their relationships. In the following these components and their interactions are described in more detail.
7.10.1. Cate Docker
Cate Docker is the containerised Cate software. It is a Docker image that provides an isolated, frozen Python environment comprising a Python 3.8 interpreter, the Cate Python Core, and all of its dependencies. This image forms lowest layer of cate service in Cate SaaS through its WebAPI. Users may also use the image for running Cate locally, on their own machines.
The source for building Cate containers is hosted at https://github.com/CCI-Tools/cate-docker and pre-build images are hosted at https://quay.io. The repository will soon be made public. In the future, Cate container images may support a way to launch both the Cate WebAPI as well as Jupyter Notebooks under a single environment. This provides users access to persistent storage for their Cate workspaces.
7.10.2. Kubernetes Cluster
Kubernetes automates container orchestration and management in cloud environments. Using Kubernetes provides load balancing, scalability and portablity of Cate SaaS to multiple cloud providers among other benefits.
7.10.3. CateHub
CateHub exploits cloud environments to spawn Cate Docker to multiple users with attached computational resources and persistant storage. Such a design pattern is very similar to JupyterHub. Hence, CateHub’s architecture is derived from it. At its core is a so-called hub server that facilitates interaction with its sub-components that handle its house keeping tasks. The hub can be managed over its REST API. This REST API is used in Cate App to start a dedicated Cate WebAPI service for each user. The relevant sub-components of CateHub are described here for illustrating their roles in Cate SaaS.
The spawner component of the hub, communicates with the Kubernetes Cluster via its Kubernetes API to spawn pods containing Cate docker containers. A customisable configuration requests computational resources and persistent storage for each user. Each pod, once ready, exposes Cate WebAPI to the internal cluster network.
The proxy component, configurable-http-proxy, a nodejs application acts as front-end gateway to a CateHub instance for all external requests from users. By default, it forwards all requests to the hub component. The proxy is mainly responsible for reverse proxying individual user’s requests to their cate pod’s WebAPI service. Being the front end to user’s requests, the proxy also logs usage activities of each user to help the hub shutting down pods upon inactivity to save resources. Currently, this is configured to be one hour of idleness.
The authentication component is used for authenticating user access, this may also be bypassed by external authentication providers such as KeyCloak.
Basing CateHub on JupyterHub has the advantage of a reliable, well-tested framework and, furthermore, JupyterHub’s deployment documentation also serves as reference for CateHub deployment on multiple cloud providers.
In its simplest use case, deployment of CateHub amounts to following JupyterHub deployment on kubernetes using helm charts at: https://zero-to-jupyterhub.readthedocs.io/en/latest/ and overiding its default container image in config.yaml like:
name: catehub
image:
name: quay.io/bcdev/cate-webapi-k8s
tag: 2.1.0.dev0.build15
extraEnv:
CATE_USER_ROOT: "/home/cate"
kubespawner_override:
cmd: ["/bin/bash", "-c", "source activate cate-env && cate-webapi-start -v -p 8888 -a 0.0.0.0"]
7.10.4. Cate App
Cate App is a Single Page Application (SPA) that acts as a user’s frontend to the Cate cloud service.. This is also deployed on the Kubernetes cluster and is, thereby, load balanced by a so-called Ingress component (default is a NGINX server) of Kubernetes. In fact, all the requests to CaaS are load balanced by Ingress. Upon authentication, Cate App makes request to CateHub to start Cate WebAPI service and from there on communicates to the pod containing Cate WebAPI using WebSockets.
The source for Cate App is hosted at: https://github.com/CCI-Tools/cate-webui. The Cate App may be installed locally via the web-interface.
This paragraph summarizes the flow of requests from perspective of Cate App. When a user submits a username
and password in Cate App, Keycloak or authentication component of CateHub authenticates the
credentials and returns an access token that permits further requests to CateHub. Cate App makes request to REST API of
CateHub to spawn a WebAPI service with resources. The spawner component of CateHub facilitates this request to
Kubernetes. Upon success, Hub component of CateHub makes changes to the proxy component to
reverse proxy all the requests on /user/${username} to the pod.
In future this deployment may be extended with a additional component, Dask Cluster, to provide additional computational resources to cate operations.
7.10.5. JASMIN Cloud
This section describes an example deployment of Cate SaaS on JASMIN. JASMIN is an infrastructure facility funded by the Natural Environment Research Council and the UK Space Agency and delivered by the Science and Technology Facilities Council. Among its services, it provides a Cluster-as-a-Service (CaaS) for its users, comprising Kubernetes clusters and identitiy management clusters. It’s co-location with CCI data store allows high network bandwidth for large datasets, making it ideal for hosting Cate SaaS.
JASMIN Kubernetes CaaS along with its identity management server, KeyCloak, is used to deploy Cate SaaS. KeyCloak facilitates access to the kubernetes cluster for administration and optionally can be used to authenticate cate users via its interface to various identity providers.
7.10.6. Cate SaaS Component Interactions
This chapter describes and illustrates the interactions between different Cate SaaS components.

Fig. 7.12 Cate SaaS Component Interactions.
The Cate GUI is started by the user either by using the Cate App from an internet browser or on the local machine. By logging into the CateHub server from the Cate GUI, a new Cate Web API service will be spawned and “owned” by the user for the duration of the session.
Once the Cate Web API service is up and running, the Cate GUI directly communicates with it. User interactions, such as operation invocations are translated into Cate Web API requests which will then be executed remotely in the cloud environment. Data access operations are further delegated to the ESA Open Data Portal (ODP) service. Once data access and computations have been completed, the Cate Web API returns the results to the Cate GUI which consecutively visualises the results.
If the users logs out, or after a configurable time of idleness, the Cate Web API instances are shut down to free allocated cloud resources.